Linux中的零拷贝#
1. 数据拷贝基础过程#
在Linux系统内部缓存和内存容量都是有限的,更多的数据都是存储在磁盘中。对于Web服务器来说,经常需要从磁盘中读取数据的内存,然后通过网卡传输给用户
1.1 仅CPU方式#
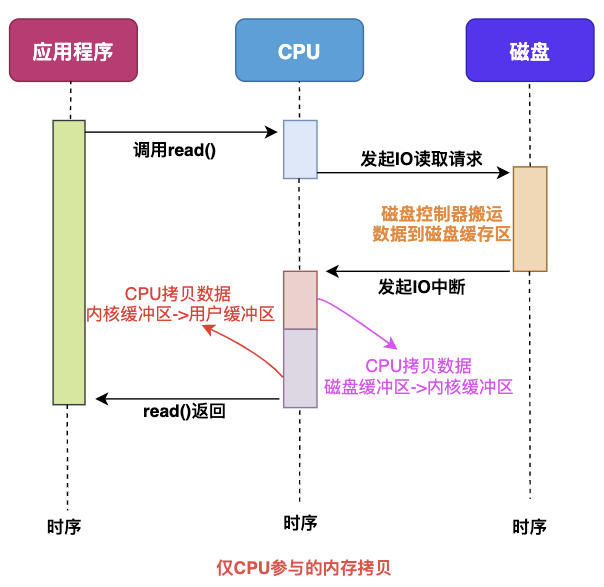
当应用程序需要读取磁盘数据时,调用read()从用户态陷入内核态,read()这个系统调用最终由CPU来完成
CPU向磁盘发起I/O请求,磁盘收到之后开始准备数据
磁盘将数据放到磁盘缓冲区之后,向CPU发起I/O中断,告诉CPU数据已经ready了
CPU收到磁盘控制器的I/O中断之后,开始拷贝数据,完成之后read()返回,再从内核态切换到用户态
1.2 CPU&DMA方式#
CPU的时间宝贵,让它做杂活就是浪费资源
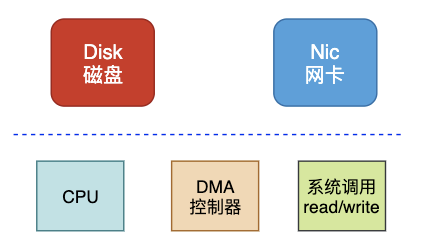
直接内存访问(Direct Memory Access),是一种硬件设备绕开COU独立直接访问内存的机制。所以DMA再一定程度上解放了CPU,把之前CPU的杂货让硬件直接自己做了,提高了CPU效率。
目前支持DMA的硬件包括:网卡、声卡、显卡、洗盘控制器等。
有了DMA的参与之后的流程发生了一些变化
最主要的变化是,CPU不再和磁盘直接交互,而是DMA和磁盘交互并且将数据从磁盘缓冲区拷贝到内核缓冲区,之后的过程类似。
1
|
无论从仅CPU的方式和DMA&CPU的方式,都存在多次冗余数据拷贝和内核态&用户态的切换。
|
2. 普通模式数据交互#
一次完成的数据交互包括几个部分:系统调用syscall、CPU、DMA、网卡、磁盘等
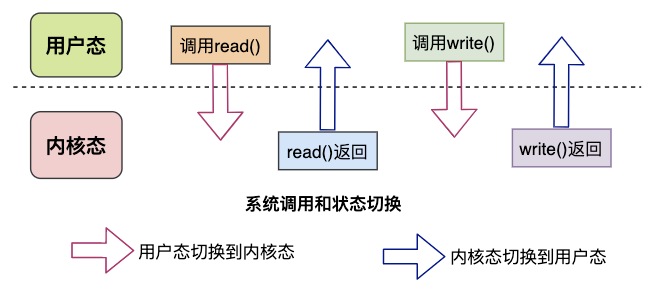
系统调用syscall是应用程序和内核交互的桥梁,每次进行调用/返回就会产生两次切换:
调用syscall从用户态切换到内核态
syscall返回从内核台切换到用户态
下图是完整的数据拷贝过程简图:
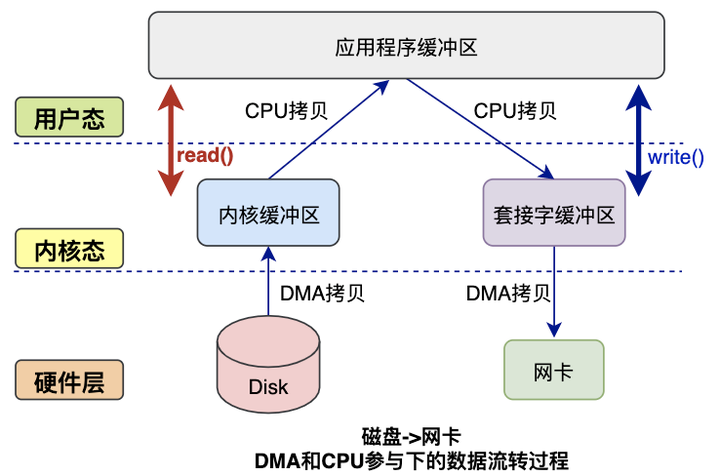
读数据过程:
应用程序要读取磁盘数据,调用read()函数从而实现用户态切换内核态,这是第一次切换
DMA控制器将数据从磁盘拷贝到内核缓冲区,这是第一次DMA拷贝
CPU将数据从内核缓冲区复制到用户缓冲区,这是第一次CPU拷贝
CPU拷贝完成之后,read()函数返回实现内核态切换用户态,这是第2次状态切换
写数据过程:
应用程序要向网卡写数据,调用write()函数实现用户态切换内核态,这是第一次切换
CPU将用户缓冲区数据拷贝到内核缓冲区,这是第一次CPU拷贝
DMA控制器将数据从内核缓冲区复制到socket缓冲区,这是第一次DMA拷贝
完成拷贝之后,write()函数返回实现内核态切换用户态,这是第二次切换
综上所述:
读过程涉及2次空间切换、1次DMA拷贝、1次CPU拷贝
写过程涉及2次空间切换,1次DMA拷贝,1次CPU拷贝
可见传统模式下,涉及多次空间切换和数据冗余拷贝,效率并不高,接下来就该零拷贝技术出场了。
3. 零拷贝技术#
3.1 出现原因#
可以看到,如果应用程序读取磁盘数据,从内核缓冲区到用户缓冲区,再从用户缓冲区到内核缓冲区。两次数据拷贝都需要CPU的参与,并且涉及用户态与内核态的多次切换,加重了CPU负担。需要降低冗余数据拷贝,解放CPU,这就是零拷贝技术。
3.2 解决思路#
目前来看,零拷贝技术的几个实现手段包括: mmap+write、sendfile、sendfile+DMA收集、splice等。
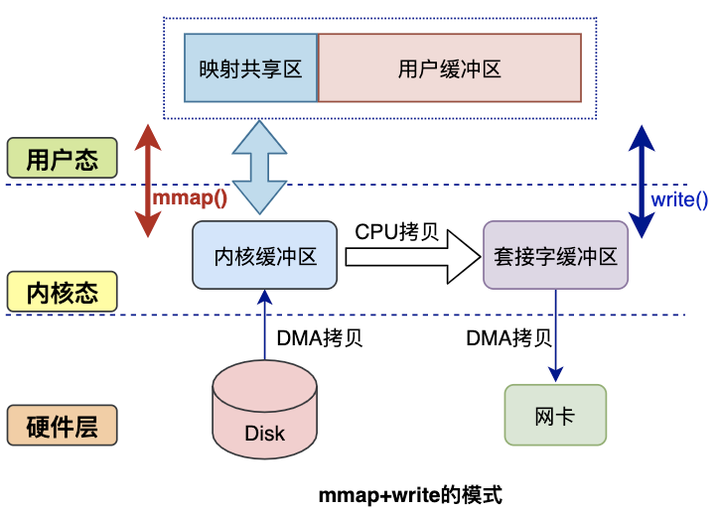
3.2.1 mmap方式#
mmap是Linux提供的一种内存映射文件的机制,它实现了将内核中读缓冲区地址与用户空间缓冲区地址进行映射,从而实现内核缓冲区与用户缓冲区的共享。
这样就减少了一次用户态和内核态的CPU拷贝,但是在内核空间仍有一次CPU拷贝
mmap对大文件传输有一定优势,但是小文件可能出现碎片,并且在多个进程同时操作文件时可能产生coredump的signal。
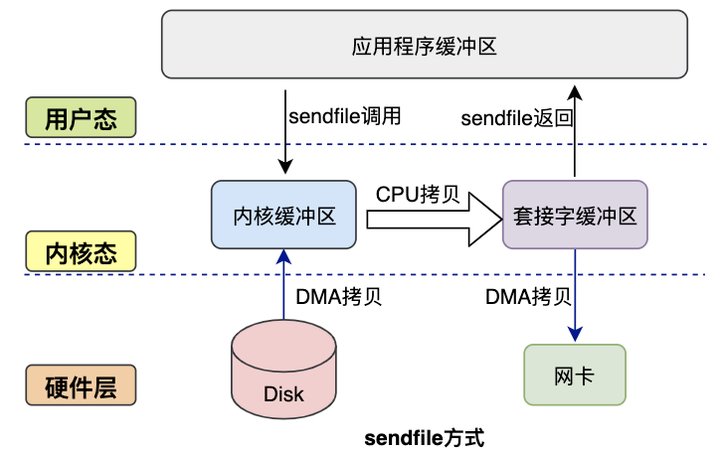
3.2.2 sendfile方式#
mmap+write方式有一定改进,但是由系统调用引起的状态切换并没有减少。
sendfile系统调用实在Linux内核2.1版本中被引入,它建立了两个文件之间的传输通道。
sendfile方式只使用一个函数就可以完成之前的read+write和mmap+write的功能,这样就减少了2次状态切换,由于数据不经过用户缓冲区,因此该数据无法被修改
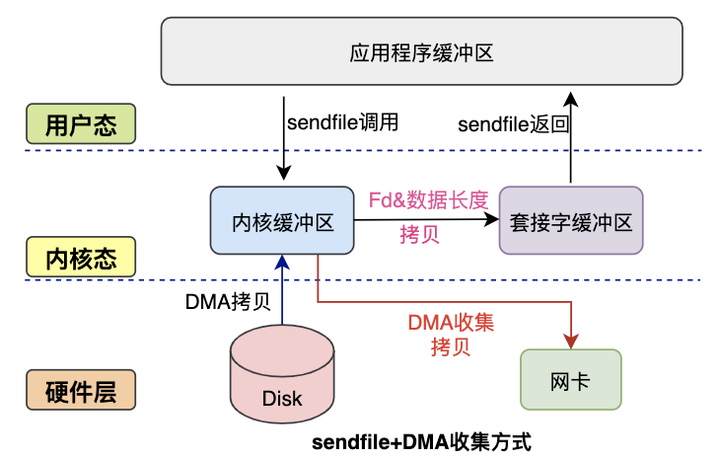
3.2.3 sendfile+DMA收集#
Linux2.4内核对 sendfile系统调用进行优化,但是需要硬件DMA控制器的配合。
升级之后的sendfile将内核空间缓冲区中对应的数据描述信息记录到socket缓冲区中。
DMA控制器根据socket缓冲区中的地址和偏移量将数据从内核缓冲区拷贝到网卡中,从而省去了内核空间中仅剩的一次CPU拷贝
这种方式有2次状态切换,0次CPU拷贝、2次DMA拷贝,但是仍然无法对数据进行修改,并且需要硬件层面DMA的支持,并且sendfile只能将文件的数据拷贝到socket描述符上,有一定的局限性。
3.2.4 splice方式#
splice系统调用是Linux在2.6版本引入的,其不需要硬件支持,并且不再限定于socket上,实现两个普通文件之间的数据零拷贝。
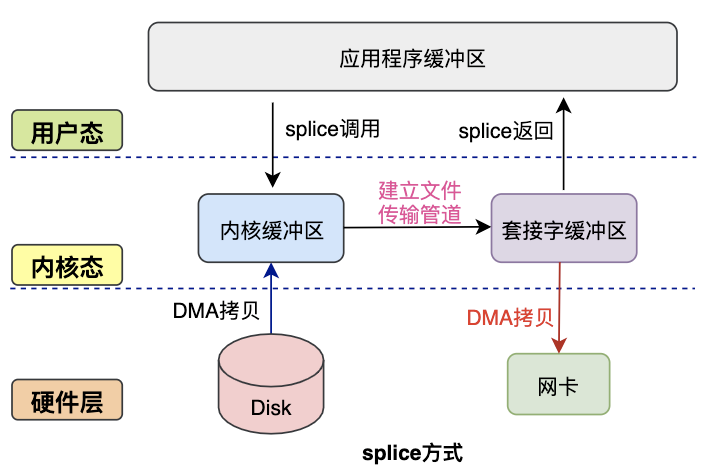
splice系统调用可以在内核缓冲区和socket缓冲区之间建立管道来传输数据,避免了两者之间的CPU拷贝操作。
JAVA NIO零拷贝#
在Java NIO中的
通道就相当于操作系统的内核空间的缓冲区,而缓冲区对应的相当于操作系统的用户空间中的用户缓冲区。
通道是全双工的(双向运输),它既可能是读缓冲区,也可能是网络缓冲区
缓冲区分为堆内存和堆外内存,这是通过malloc分配出来的用户态内存。
堆外内存在使用后需要应用程序手动回收,而堆内存在数据GC时可能被自动回收。因此,在使用HeapBuffer读写数据时,为了避免缓冲区数据因为GC丢失,NIO会先把HeapBuffer内部的数据拷贝到一个临时的DirectBuffer中的本地内存,这个拷贝涉及到sun.misc.Usafe.copyMemory()的调用,背后的实现原理于memcpy()类似。最后,将临时生成的DirectBuffer内部的数据的内存地址传给I/O调用函数,这样就避免了再去访问Java对象处理I/O读写。
MAppedByteBuffer#
MappedBytyBuffer是NIO基于"内存映射(mmap)“这种零拷贝方式的提供的一种实现,它继承自ByteBuffer。FileChannel定义了一个map()方法,它可以把一个文件从position位置开始的size大小的区域映射为内存映像文件。抽象方法map()方法在FileChannel中的定义如下:
1
2
|
public abstract MappedByteBuffer map(MapMode mode, long position, long size)
throws IOException;
|
MappedByteBuffer相比ByteBuffer新增了fore()、load()和isLoad()三个重要方法:
fore(): 对于处于READ_WRITE模式下的缓冲区,把对缓冲区内容的修改强制刷新到本地文件。
load(): 将缓冲区的内容载入到物理内存中,并返回这个缓冲区的引用
isLoad(): 如果缓冲区的内容在物理内存中,则返回true,否则返回false。
下面给出一个利用MappedByteBuffer对文件进行读写的使用示例:
1
2
3
|
private final static String CONTENT = "Zero copy implemented by MappedByteBuffer";
private final static String FILE_NAME = "/mmap.txt";
private final static String CHARSET = "UTF-8";
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
@Test
public void writeToFileByMappedByteBuffer() {
Path path = Paths.get(getClass().getResource(FILE_NAME).getPath());
byte[] bytes = CONTENT.getBytes(Charset.forName(CHARSET));
try (FileChannel fileChannel = FileChannel.open(path, StandardOpenOption.READ,
StandardOpenOption.WRITE, StandardOpenOption.TRUNCATE_EXISTING)) {
MappedByteBuffer mappedByteBuffer = fileChannel.map(READ_WRITE, 0, bytes.length);
if (mappedByteBuffer != null) {
mappedByteBuffer.put(bytes);
mappedByteBuffer.force();
}
} catch (IOException e) {
e.printStackTrace();
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
@Test
public void readFromFileByMappedByteBuffer() {
Path path = Paths.get(getClass().getResource(FILE_NAME).getPath());
int length = CONTENT.getBytes(Charset.forName(CHARSET)).length;
try (FileChannel fileChannel = FileChannel.open(path, StandardOpenOption.READ)) {
MappedByteBuffer mappedByteBuffer = fileChannel.map(READ_ONLY, 0, length);
if (mappedByteBuffer != null) {
byte[] bytes = new byte[length];
mappedByteBuffer.get(bytes);
String content = new String(bytes, StandardCharsets.UTF_8);
assertEquals(content, "Zero copy implemented by MappedByteBuffer");
}
} catch (IOException e) {
e.printStackTrace();
}
}
|
下面介绍map()方法的底层实现原理。map()方法是java.nio.channels.FileChannel的抽象方法,由子类sun.nio.ch.FIleChannelImpl.java实现,下面是和内存映射相关的核心代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
public MappedByteBuffer map(MapMode mode, long position, long size) throws IOException {
int pagePosition = (int)(position % allocationGranularity);
long mapPosition = position - pagePosition;
long mapSize = size + pagePosition;
try {
addr = map0(imode, mapPosition, mapSize);
} catch (OutOfMemoryError x) {
System.gc();
try {
Thread.sleep(100);
} catch (InterruptedException y) {
Thread.currentThread().interrupt();
}
try {
addr = map0(imode, mapPosition, mapSize);
} catch (OutOfMemoryError y) {
throw new IOException("Map failed", y);
}
}
int isize = (int)size;
Unmapper um = new Unmapper(addr, mapSize, isize, mfd);
if ((!writable) || (imode == MAP_RO)) {
return Util.newMappedByteBufferR(isize, addr + pagePosition, mfd, um);
} else {
return Util.newMappedByteBuffer(isize, addr + pagePosition, mfd, um);
}
}
|
map()方法通过本地方法map0()为文件分配一块虚拟内存,作为它的内存映射区域,然后返回这块内存映射区域的起始地址。
文件映射需要在Java堆中创建一个MappedByteBuffer的实例。如果第一次文件映射导致OOM,则手动触发垃圾回收,休眠100ms后再次尝试映射,如果失败则抛出异常。
通过Util的newMappedByteBUffer方法或者newMappedByteBufferR方法反射创建一个DirectByteBuffer实例,其中DirectByteBuffer是MappedByteBUffer的子类。
map()方法返回的是内存映射区域的起始地址,通过(起始地址+偏移量)就可以获取指定内存的数据。这样一定程度上替代了read或write()方法,底层直接采用sun.misc.Unsafe类的getByte()和putByte()方法对数据进行读写。
1
|
private native long map0(int prot, long position, long mapSize) throws IOException;
|
上面是本地方法map0的定义,它通过JNI调用底层C的实现,这个native函数的实现位于JDK源码包下。
native/sun/nio/ch/FileChannelImpl.c这个源文件里
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
JNIEXPORT jlong JNICALL
Java_sun_nio_ch_FileChannelImpl_map0(JNIEnv *env, jobject this,
jint prot, jlong off, jlong len)
{
void *mapAddress = 0;
jobject fdo = (*env)->GetObjectField(env, this, chan_fd);
jint fd = fdval(env, fdo);
int protections = 0;
int flags = 0;
if (prot == sun_nio_ch_FileChannelImpl_MAP_RO) {
protections = PROT_READ;
flags = MAP_SHARED;
} else if (prot == sun_nio_ch_FileChannelImpl_MAP_RW) {
protections = PROT_WRITE | PROT_READ;
flags = MAP_SHARED;
} else if (prot == sun_nio_ch_FileChannelImpl_MAP_PV) {
protections = PROT_WRITE | PROT_READ;
flags = MAP_PRIVATE;
}
mapAddress = mmap64(
0, /* Let OS decide location */
len, /* Number of bytes to map */
protections, /* File permissions */
flags, /* Changes are shared */
fd, /* File descriptor of mapped file */
off); /* Offset into file */
if (mapAddress == MAP_FAILED) {
if (errno == ENOMEM) {
JNU_ThrowOutOfMemoryError(env, "Map failed");
return IOS_THROWN;
}
return handle(env, -1, "Map failed");
}
return ((jlong) (unsigned long) mapAddress);
}
|
可以看出map0()函数最终是通过mmap65()这个函数对Linux底层内核发出的内存映射调用,mmap64()函数的原型如下:
1
2
3
|
#include <sys/mman.h>
void *mmap64(void *addr, size_t len, int prot, int flags, int fd, off64_t offset);
|
下面详细介绍以下mmap64()函数各个参数的含义以及参数可选值:
addr: 文件在用户进程空间的内存映射区中的起始地址,是一个建议的参数,通常可设置为0或null,此时由内核去决定真实的起始地址。当+flag为MAP_FIXED时,addr就是一个必选的参数,即需要提供一个存在的地址。
len:文件需要进行内存映射的长度
prot:控制用户进程对内存映射区的访问权限。
- PROT_READ: 读权限
- PROT_WRITE: 写权限
- PROT_EXEC: 执行权限
- PROT_NONE: 无权限
flags: 控制内存映射区的修改是否被多个进程共享
- MAP_PRIVATE: 对内存映射区数据的修改不会反映到真正的文件,数据修改发生时采用写时复制机制。
- MAP_SHARED: 对内存映射区的修改会同步到真正的文件,修改对共享此内存映射区的进程是可见的。
- MAP_FIXED: 不建议使用,这种模式下addr参数指定的必须的提供一个存在的addr参数。
fd: 文件描述符。每次Map操作会导致文件的引用计数加1,每次unmap操作或者结束进程会导致引用计数减1
offset: 文件偏移量。进行映射的文件位置,从文件起始地址向后的位移量
下面总结一下MappedByteBuffer的特点和不足之处:
MappedByteBuffer使用是堆外的虚拟内存,因此分配的内存大小不受JVM的-Xmx参数限制,但是也是有大小限制的。如果当文件超出Integer.MAX_VALUE字节限制时,可以通过position参数重新map文件后面的内容。
MappedByteBuffer在处理大文件时性能的确很高,但是也存在内存占用,文件关闭不确定等问题,被其打开的文件只有在垃圾回收的时候才会被关闭,而且这个时间点是不确定的。
MappedByteBuffer提供了文件映射内存的mmap()方法,也提供了释放映射内存的unmap()方法。然而unmap()是FileChannelImpl中的私有方法,无法直接显示调用。因此,用户程序需要通过Java反射的调用sun.misc.Cleaner类的clean()方法手动释放映射占用的内存区域。
1
2
3
4
5
6
7
8
9
10
11
12
|
public static void clean(final Object buffer) throws Exception {
AccessController.doPrivileged((PrivilegedAction<Void>) () -> {
try {
Method getCleanerMethod = buffer.getClass().getMethod("cleaner", new Class[0]);
getCleanerMethod.setAccessible(true);
Cleaner cleaner = (Cleaner) getCleanerMethod.invoke(buffer, new Object[0]);
cleaner.clean();
} catch(Exception e) {
e.printStackTrace();
}
});
}
|
DirectByteBuffer#
DirectByteBUffer 的对象引用位于Java 内存模型的堆里面,JVM可以对DirectByteBUffer的对象进行内存分配和回收管理,一般使用DirectByteBuffer的静态方法allocateDirect()创建DIrectByteBuffer实例并分配内存。
1
2
3
|
public static ByteBuffer allocateDirect(int capacity) {
return new DirectByteBuffer(capacity);
}
|
DirectByteBUffer内部的字节缓冲区位在于堆外的直接内存,它是通过Unsafe的本地方法allocateMemory()进行内存分配,底层调用的是操作系统的malloc()函数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
DirectByteBuffer(int cap) {
super(-1, 0, cap, cap);
boolean pa = VM.isDirectMemoryPageAligned();
int ps = Bits.pageSize();
long size = Math.max(1L, (long)cap + (pa ? ps : 0));
Bits.reserveMemory(size, cap);
long base = 0;
try {
base = unsafe.allocateMemory(size);
} catch (OutOfMemoryError x) {
Bits.unreserveMemory(size, cap);
throw x;
}
unsafe.setMemory(base, size, (byte) 0);
if (pa && (base % ps != 0)) {
address = base + ps - (base & (ps - 1));
} else {
address = base;
}
cleaner = Cleaner.create(this, new Deallocator(base, size, cap));
att = null;
}
|
除此之外,初始化DIrectByteBuffer时还会创建一个Deallocator线程,并通过Cleaner的freeMemory()方法来直接对内存进行回收操作,freeMemory()底层调用的是操作系统的free()函数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
private static class Deallocator implements Runnable {
private static Unsafe unsafe = Unsafe.getUnsafe();
private long address;
private long size;
private int capacity;
private Deallocator(long address, long size, int capacity) {
assert (address != 0);
this.address = address;
this.size = size;
this.capacity = capacity;
}
public void run() {
if (address == 0) {
return;
}
unsafe.freeMemory(address);
address = 0;
Bits.unreserveMemory(size, capacity);
}
}
|
由于使用DirectByteBuffer分配的是系统本地的内存,不在JVM的管控范围之内,因此直接内存的回收和堆内存的回收不同,直接内存如果使用不当,很容易造成OutOfMemoryError。
说了这么多,那么DirectByteBuffer和零拷贝有什么关系?前面有提到在MappedByteBuffer进行内存映射时,它的map()方法会通过Util.newMappedByteBuffer()来创建一个缓冲区实例,初始化代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
static MappedByteBuffer newMappedByteBuffer(int size, long addr, FileDescriptor fd,
Runnable unmapper) {
MappedByteBuffer dbb;
if (directByteBufferConstructor == null)
initDBBConstructor();
try {
dbb = (MappedByteBuffer)directByteBufferConstructor.newInstance(
new Object[] { new Integer(size), new Long(addr), fd, unmapper });
} catch (InstantiationException | IllegalAccessException | InvocationTargetException e) {
throw new InternalError(e);
}
return dbb;
}
private static void initDBBRConstructor() {
AccessController.doPrivileged(new PrivilegedAction<Void>() {
public Void run() {
try {
Class<?> cl = Class.forName("java.nio.DirectByteBufferR");
Constructor<?> ctor = cl.getDeclaredConstructor(
new Class<?>[] { int.class, long.class, FileDescriptor.class,
Runnable.class });
ctor.setAccessible(true);
directByteBufferRConstructor = ctor;
} catch (ClassNotFoundException | NoSuchMethodException |
IllegalArgumentException | ClassCastException x) {
throw new InternalError(x);
}
return null;
}});
}
|
DirectByteBuffer是MappedByteBuffer的具体实现类。实际上,Util.newMappedByteBUffer()方法通过反射机制获取DirectByteBuffer的构造器,然后创建一个DirectByteBUffer的实例,对应的是一个单独用于内存映射的构造方法:
1
2
3
4
5
6
|
protected DirectByteBuffer(int cap, long addr, FileDescriptor fd, Runnable unmapper) {
super(-1, 0, cap, cap, fd);
address = addr;
cleaner = Cleaner.create(this, unmapper);
att = null;
}
|
因此除了允许分配操作系统的直接内存之外,DirectByteBuffer本身也具有文件映射的功能,这里不做过多说明。我们需要关注的是,DirectByteBuffer在MappedByteBuffer的基础上提供了内存映像文件的随机读取get()和写入write()操作。
1
2
3
4
5
6
7
|
public byte get() {
return ((unsafe.getByte(ix(nextGetIndex()))));
}
public byte get(int i) {
return ((unsafe.getByte(ix(checkIndex(i)))));
}
|
1
2
3
4
5
6
7
8
9
|
public ByteBuffer put(byte x) {
unsafe.putByte(ix(nextPutIndex()), ((x)));
return this;
}
public ByteBuffer put(int i, byte x) {
unsafe.putByte(ix(checkIndex(i)), ((x)));
return this;
}
|
内存映像文件的随机读写都是借助ix()方法实现定位的,ix()方法通过内存映射空间的内存首地址和给定偏移量i计算出指针地址,然后由unsafe类的get()和put()方法和对指针指向的数据进行读取或写入。
1
2
3
|
private long ix(int i) {
return address + ((long)i << 0);
}
|
FileChannel#
FileChannel是一个用户文件读写,映射和操作的通道,同时它在并发环境下是线程安全的,基于FileInputStream、FileOutputStream或者RandomAccessFile的getChannel()方法可以创建并打开一个文件通道。FIleChannel定义了transferFrom()和transferTo()两个抽象方法,它通过在通道和通道之间建立连接实现数据传输的。
transferTo(): 通过FileChannel把文件里面的源数据写入一个WritableByteChannel的目的通道
1
2
|
public abstract long transferTo(long position, long count, WritableByteChannel target)
throws IOException;
|
1
2
|
public abstract long transferFrom(ReadableByteChannel src, long position, long count)
throws IOException;
|
下面给出FileChannel利用transferTo()和transferFrom()方法进行数据传输的使用示例:
1
2
3
4
|
private static final String CONTENT = "Zero copy implemented by FileChannel";
private static final String SOURCE_FILE = "/source.txt";
private static final String TARGET_FILE = "/target.txt";
private static final String CHARSET = "UTF-8";
|
首先在类加载根路径下创建source.txt和target.txt两个文件,对源文件source.txt文件写入初始化数据。
1
2
3
4
5
6
7
8
9
10
11
|
@Before
public void setup() {
Path source = Paths.get(getClassPath(SOURCE_FILE));
byte[] bytes = CONTENT.getBytes(Charset.forName(CHARSET));
try (FileChannel fromChannel = FileChannel.open(source, StandardOpenOption.READ,
StandardOpenOption.WRITE, StandardOpenOption.TRUNCATE_EXISTING)) {
fromChannel.write(ByteBuffer.wrap(bytes));
} catch (IOException e) {
e.printStackTrace();
}
}
|
对于transferTo()方法而言,目的通道toChannel可以是任意的单向字节通道WritableByteChannel;而对于transferFrom()方法而言,源通道fromChannel可以是任意的单项字节读通道ReadableByteChannel。其中,FileChannel、SocketChannel和DatagramChannel等通道实现了WriteByteChannel和ReadableByteChannel接口,都是同时支持读写的双向通道。为了方便测试,下面给出基于FileChannel完成channel-to-channel的数据传输示例:
1
2
3
4
5
6
7
8
9
10
11
|
@Test
public void transferTo() throws Exception {
try (FileChannel fromChannel = new RandomAccessFile(
getClassPath(SOURCE_FILE), "rw").getChannel();
FileChannel toChannel = new RandomAccessFile(
getClassPath(TARGET_FILE), "rw").getChannel()) {
long position = 0L;
long offset = fromChannel.size();
fromChannel.transferTo(position, offset, toChannel);
}
}
|
通过transferFrom()将fromChannel中的数据拷贝到toChannel:
1
2
3
4
5
6
7
8
9
10
11
|
@Test
public void transferFrom() throws Exception {
try (FileChannel fromChannel = new RandomAccessFile(
getClassPath(SOURCE_FILE), "rw").getChannel();
FileChannel toChannel = new RandomAccessFile(
getClassPath(TARGET_FILE), "rw").getChannel()) {
long position = 0L;
long offset = fromChannel.size();
toChannel.transferFrom(fromChannel, position, offset);
}
}
|
下面介绍transferTo()和transferFrom()方法的底层实现原理,这两个方法也是java.nio.channels.FIlwChannel的抽象方法,由子类sun.nio.ch.FileChannelImpl.java实现。transferTo()和transferFrom()底层都是基于sendfile实现数据传输的,其中FileChannelImpl.java定义了3个常量,用于标示当前操作系统的内核是否支持sendfile以及sendfile的相关特性。
1
2
3
|
private static volatile boolean transferSupported = true;
private static volatile boolean pipeSupported = true;
private static volatile boolean fileSupported = true;
|
下面以transfer()的源码实现为例。FIleChannelImpl首先执行transferToDirectly()方法,以sendfile的零拷贝方式数据拷贝。如果系统内核不支持sendfile,进一步执行transferToTrustedChannel()方法,以mmap()的零拷贝方式进行内存映射,这种情况下目的通道必须是FileChannelImpl或者SelChImpl类型。如果以上两步都失败了,则执行transferToArbitraryChannel()方法,基于传统的I/O方式完成读写,具体步骤是初始化一个临时的DirectBuffer,将源通道FileChannel的数据读取到DirectBuffer,再写入目的通道WritableByteChannel里面。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
public long transferTo(long position, long count, WritableByteChannel target)
throws IOException {
// 计算文件的大小
long sz = size();
// 校验起始位置
if (position > sz)
return 0;
int icount = (int)Math.min(count, Integer.MAX_VALUE);
// 校验偏移量
if ((sz - position) < icount)
icount = (int)(sz - position);
long n;
if ((n = transferToDirectly(position, icount, target)) >= 0)
return n;
if ((n = transferToTrustedChannel(position, icount, target)) >= 0)
return n;
return transferToArbitraryChannel(position, icount, target);
}
|
接下来重点分析一下transferToDirectly()方法的实现,也就是transferTo()通过sendfile实现零拷贝的精髓所在。可以看到,transferToDirectlyInternal()方法先获取到目的的通道WritableByteChannel的文件描述符targetFD,获取同步锁然后执行transferToDirectlyInternal()方法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
private long transferToDirectly(long position, int icount, WritableByteChannel target)
throws IOException {
// 省略从target获取targetFD的过程
if (nd.transferToDirectlyNeedsPositionLock()) {
synchronized (positionLock) {
long pos = position();
try {
return transferToDirectlyInternal(position, icount,
target, targetFD);
} finally {
position(pos);
}
}
} else {
return transferToDirectlyInternal(position, icount, target, targetFD);
}
}
|
最终由transferToDirectlyInternal()调用本地方法transferTo0(),尝试以sendfile的方式进行数据传输。如果系统内核完全不支持sendfile,比如Windows操作系统,则返回UNSUPPORTED并把transferSupported标识为false。如果系统内核不支持sendfile的一些特性,比如说低版本的Linux内核不支持DMA gather copy 操作,则返回 UNSUPPORTED_CASE 并把pipeSupported 或者 fileSupported标识为false。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
private long transferToDirectlyInternal(long position, int icount,
WritableByteChannel target,
FileDescriptor targetFD) throws IOException {
assert !nd.transferToDirectlyNeedsPositionLock() ||
Thread.holdsLock(positionLock);
long n = -1;
int ti = -1;
try {
begin();
ti = threads.add();
if (!isOpen())
return -1;
do {
n = transferTo0(fd, position, icount, targetFD);
} while ((n == IOStatus.INTERRUPTED) && isOpen());
if (n == IOStatus.UNSUPPORTED_CASE) {
if (target instanceof SinkChannelImpl)
pipeSupported = false;
if (target instanceof FileChannelImpl)
fileSupported = false;
return IOStatus.UNSUPPORTED_CASE;
}
if (n == IOStatus.UNSUPPORTED) {
transferSupported = false;
return IOStatus.UNSUPPORTED;
}
return IOStatus.normalize(n);
} finally {
threads.remove(ti);
end (n > -1);
}
}
|
本地方法transferTo0()通过JNI调用底层C的函数,这个native函数同样位于JDK源码包下的 native.sun/nio/ch/FileChannelImol.c源文件里面。JNI函数java_sun_nio_ch_FileChannelImpl_transferTo0()基于条件编译对不同的系统进行预编译,下面是JDK基于Linux系统内核对transferTo()提供的调用封装。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
#if defined(__linux__) || defined(__solaris__)
#include <sys/sendfile.h>
#elif defined(_AIX)
#include <sys/socket.h>
#elif defined(_ALLBSD_SOURCE)
#include <sys/types.h>
#include <sys/socket.h>
#include <sys/uio.h>
#define lseek64 lseek
#define mmap64 mmap
#endif
JNIEXPORT jlong JNICALL
Java_sun_nio_ch_FileChannelImpl_transferTo0(JNIEnv *env, jobject this,
jobject srcFDO,
jlong position, jlong count,
jobject dstFDO)
{
jint srcFD = fdval(env, srcFDO);
jint dstFD = fdval(env, dstFDO);
#if defined(__linux__)
off64_t offset = (off64_t)position;
jlong n = sendfile64(dstFD, srcFD, &offset, (size_t)count);
return n;
#elif defined(__solaris__)
result = sendfilev64(dstFD, &sfv, 1, &numBytes);
return result;
#elif defined(__APPLE__)
result = sendfile(srcFD, dstFD, position, &numBytes, NULL, 0);
return result;
#endif
}
|
对Linux、Solaris以及Apple系统而言,transferTo0()函数底层会执行sendfile64这个系统调用完成零拷贝操作,sendfile64()函数原型如下:
1
2
3
|
#include <sys/sendfile.h>
ssize_t sendfile64(int out_fd, int in_fd, off_t *offset, size_t count);
|
下面简单介绍一下sendfile64()函数各个参数的含义:
out_fd: 待写入的文件描述符
in_fd: 待读取的文件描述符
offset: 指定in_fd对应文件流的读取位置,如果为空,则默认从起始位置开始
count: 指定在文件描述符in_fd和out_fd之间传输的字节数
