上午两节课睡过了,就没去了,吃了个早饭,还有一堆事情没有做,就开始先把昨晚没弄完的python词频分析的代码给写完了。做一个记录吧,防止以后用得着
工具
工具:python3.7 Vscode wordcloud jieba 等获取数据源
点击Tim左上角头像
要用txt导出到任意盘,接下来就是要对导出的文件进行数据分析
下载对应库
到官方网站下载对应包 传送门 重要提醒:通过cmd中输入 Python -V 来查看python版本并下载相应的安装包,同时注意python是32位的还是64位的,我这里是32位的 下载完成后,进入刚刚下载该文件的路径,使用pip3 install wordcloud-1.3.3-cp-37-cp-37-win_amd32-whl命令开始安装, 这样 wordcloud就安装完成了。 接下来还要安装jieba matplotlib scipy 均使用 pip3 install xxx 即可代码
- 首先过滤掉txt文件中无用的信息,比如时间,以及聊天的名片,避免词云中都是无效信息,并用jieba进行分词
|
|
通过这步在E盘中得到了一个q1.txt文件,打开会发现变的整洁干净了许多.
2.再新建一个.py文件,用到wordcloud库来绘制词云图
|
|
做出的结果图





挺好玩的,就多测试了几个群,就这样
对词频出现次数进行统计,并生成统计表
直接上代码:
|
|
这段代码结合上面分词的代码,即可生成统计表,近期来群里关键字出现的字眼一目了然
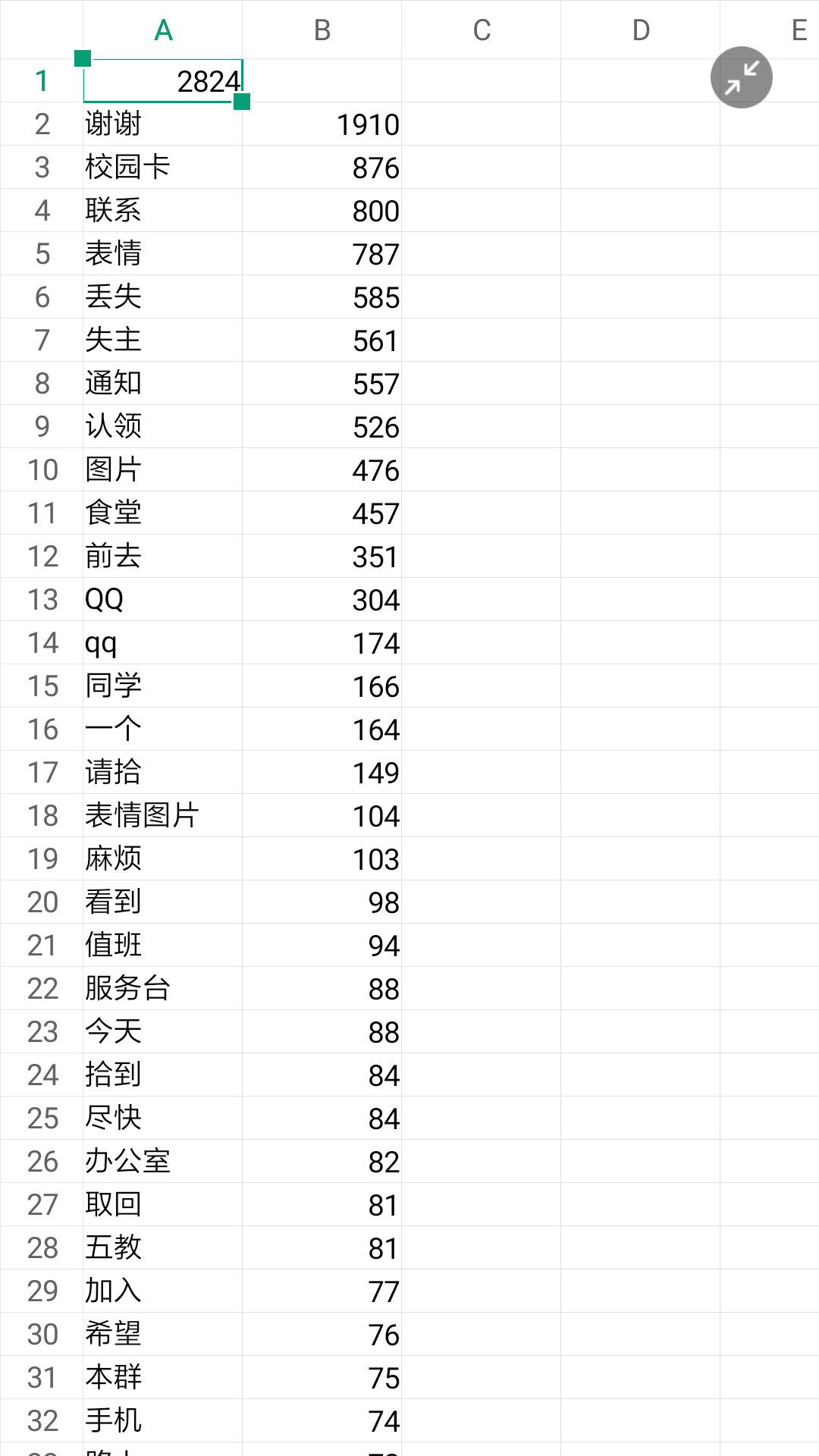 失物招领群1词频统计
谢谢的次数即代表我们一个月发过的消息总数,因为我们要求每条消息后面必须加个谢谢
由图可见,我们一个月发了1910条消息
其中校园卡类876条
寻物消息585条
失物消息526条
身份证消息41条 等等
失物招领群1词频统计
谢谢的次数即代表我们一个月发过的消息总数,因为我们要求每条消息后面必须加个谢谢
由图可见,我们一个月发了1910条消息
其中校园卡类876条
寻物消息585条
失物消息526条
身份证消息41条 等等